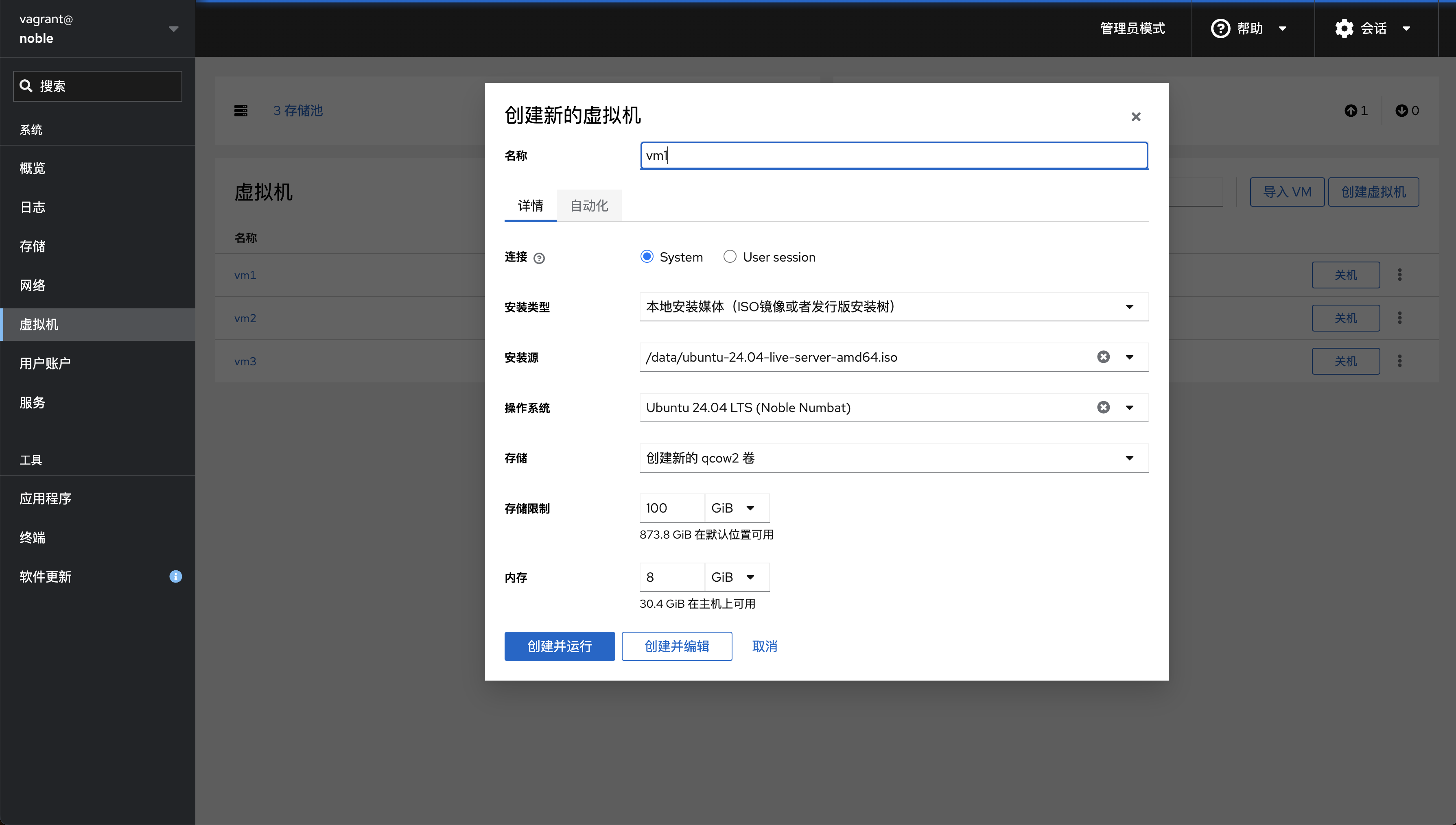
部署计划:先创建一台虚拟机vm1,安装docker以及k8s组件,然后克隆两台新的vm2/vm3,组合成一个小型的k8s集群
虚拟机准备 创建vm1 创建虚拟机vm1,以下就不展示繁琐的系统安装过程了
配置vm1 根据教程:安装docker并部署registry服务 安装好containerd,再执行下面的配置
系统配置修改 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf overlay br_netfilter EOF sudo modprobe overlaysudo modprobe br_netfiltercat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.ipv4.ip_forward = 1 EOF cat /etc/sysctl.d/k8s.confsudo sysctl --system
关闭swap 关闭swap并移除文件
1 2 3 4 5 6 7 8 9 10 11 12 13 sudo swaponsudo swapoff /swap.imgsudo rm /swap.imgsudo vi /etc/fstab
registry证书导入 私有registry使用self-signed证书,kubeadm拉取时会报错,故将证书添加到vm
1 2 3 4 5 6 7 8 scp noname.io.crt noname@192.168.122.11:/home/noname/ sudo cp noname.io.crt /usr/local/share/ca-certificates/sudo update-ca-certificatessudo systemctl restart containerdsudo systemctl restart docker
containerd设置 修改/etc/containerd/config.toml,设置cgroup driver为systemd,同时可以修改pause版本,version是必须的,否则不生效,缩进非必要,可以删除
1 2 3 4 5 6 7 8 9 10 version = 2 [plugins] [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc] runtime_type = "io.containerd.runc.v2" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] SystemdCgroup = true [plugins."io.containerd.grpc.v1.cri"] sandbox_image = "registry.noname.io:5000/pause:3.10"
重启containerd服务
1 sudo systemctl restart containerd
执行命令输出生效中的配置,验证配置是否跟预期一致
1 containerd config dump | grep SystemdCgroup
docker配置(可选) k8s与docker分手后,vm只需要一个containerd就够了,但如果你同时也安装了docker,也可以修改/etc/docker/daemon.json
1 2 3 4 { "exec-opts" : [ "native.cgroupdriver=systemd" ] , "insecure-registries" : [ "registry.noname.io:5000" ] }
重启docker服务
1 sudo systemctl restart docker
镜像准备(可选) 为了避免kubeadm init长时间卡在镜像拉取上,可以先在物理机上通过proxy拉取到本地,再推送到私有registry,最后配置从私有registry拉取image
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 docker pull registry.k8s.io/kube-apiserver:v1.31.0 docker pull registry.k8s.io/kube-controller-manager:v1.31.0 docker pull registry.k8s.io/kube-scheduler:v1.31.0 docker pull registry.k8s.io/kube-proxy:v1.31.0 docker pull registry.k8s.io/coredns/coredns:v1.11.1 docker pull registry.k8s.io/pause:3.10 docker pull registry.k8s.io/etcd:3.5.15-0 docker pull quay.io/cilium/cilium:v1.15.6 docker pull quay.io/cilium/operator-generic:v1.15.6 docker tag registry.k8s.io/kube-apiserver:v1.31.0 registry.noname.io:5000/kube-apiserver:v1.31.0 docker tag registry.k8s.io/kube-controller-manager:v1.31.0 registry.noname.io:5000/kube-controller-manager:v1.31.0 docker tag registry.k8s.io/kube-scheduler:v1.31.0 registry.noname.io:5000/kube-scheduler:v1.31.0 docker tag registry.k8s.io/kube-proxy:v1.31.0 registry.noname.io:5000/kube-proxy:v1.31.0 docker tag registry.k8s.io/coredns/coredns:v1.11.1 registry.noname.io:5000/coredns:v1.11.1 docker tag registry.k8s.io/pause:3.10 registry.noname.io:5000/pause:3.10 docker tag registry.k8s.io/etcd:3.5.15-0 registry.noname.io:5000/etcd:3.5.15-0 docker tag quay.io/cilium/cilium:v1.15.6 registry.noname.io:5000/cilium/cilium:v1.15.6 docker tag quay.io/cilium/operator-generic:v1.15.6 registry.noname.io:5000/cilium/operator-generic:v1.15.6 docker push registry.noname.io:5000/kube-apiserver:v1.31.0 docker push registry.noname.io:5000/kube-controller-manager:v1.31.0 docker push registry.noname.io:5000/kube-scheduler:v1.31.0 docker push registry.noname.io:5000/kube-proxy:v1.31.0 docker push registry.noname.io:5000/coredns:v1.11.1 docker push registry.noname.io:5000/pause:3.10 docker push registry.noname.io:5000/etcd:3.5.15-0 docker push registry.noname.io:5000/cilium/cilium:v1.15.6 docker push registry.noname.io:5000/cilium/operator-generic:v1.15.6
在虚拟机vm1中使用critool导入镜像,示例如下
1 2 3 4 5 6 7 8 sudo crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock imagesudo crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock pull registry.noname.io:5000/quay.io/cilium/operator-generic:v1.15.6sudo ctr --namespace=k8s.io image tag registry.noname.io:5000/quay.io/cilium/operator-generic:v1.15.6 quay.io/cilium/operator-generic:v1.15.6
安装组件 apt方式安装(推荐) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 sudo apt update -y && sudo apt upgrade -ysudo apt install -y apt-transport-https ca-certificates curl gpgcurl -fsSL https://pkgs.k8s.io/core:/stable:/v1.31/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.31/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.listsudo apt updatesudo apt install -y kubelet kubeadm kubectlsudo apt-mark hold kubelet kubeadm kubectlsudo systemctl enable --now kubelet
手动安装 重点 :/usr/local/bin以及/opt/cni/bin这两个目录树以及所有文件要确保所有者是root,否则会导致部署失败
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 scp kube* kubelet.service 10-kubeadm.conf noname@192.168.122.11:/home/noname/ scp crictl-v1.30.1-linux-amd64.tar.gz noname@192.168.122.11:/home/noname/ scp cni-plugins-linux-amd64-v1.5.1.tgz noname@192.168.122.11:/home/noname/ scp cilium-linux-v0.16.13.tar.gz noname@192.168.122.11:/home/noname/ scp helm-v3.15.3-linux-amd64.tar.gz noname@192.168.122.11:/home/noname/ sudo mkdir -p /opt/cni/binsudo tar -C /opt/cni/bin -xzf cni-plugins-linux-amd64-v1.5.1.tgzsudo tar -C /usr/local/bin -xzf crictl-v1.31.1-linux-amd64.tar.gzsudo tar -C /usr/local/bin -xzf cilium-linux-v0.16.13.tar.gz tar zxf helm-v3.15.3-linux-amd64.tar.gz && sudo mv linux-amd64/helm /usr/local/bin/ && rm -rf linux-amd64/ sudo mv kube* /usr/local/bin/ && chmod +x /usr/local/bin/kube*sudo mkdir -p /var/lib/kubeletcat kubelet.service | sed "s:/usr/bin:/usr/local/bin:g" | sudo tee /usr/lib/systemd/system/kubelet.servicesudo mkdir -p /usr/lib/systemd/system/kubelet.service.dcat 10-kubeadm.conf | sed "s:/usr/bin:/usr/local/bin:g" | sudo tee /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.confsudo systemctl enable --now kubeletsudo chown -R root:root /opt/cnisudo chown -R root:root /usr/local/bin
克隆vm1 以上初步准备安装好了k8s,现在还不能执行初始化部署,复制两个新的vm,避免每台机器都重复执行上面的操作,偷懒
新的vm需要确保跟旧的vm1不能有相同的MAC地址、hostname、product_uuid
hostname重命名 修改hostname
1 2 3 sudo hostnamectl hostname vm1
重新生成machine-id dhcp获取IP时,依赖的是machine-id,如果三台机器的machine-id都一样,你会发现所有vm的IP地址都是一样的,会出现冲突,比如ssh突然断线
先关闭其他机器如vm1,使用同样ssh命令如ssh noname@192.168.122.11连接到新的vm2/vm3
1 2 3 4 5 6 7 8 9 sudo rm /etc/machine-idsudo dbus-uuidgen --ensure=/etc/machine-idsudo cat /sys/class/dmi/id/product_uuidsudo reboot now
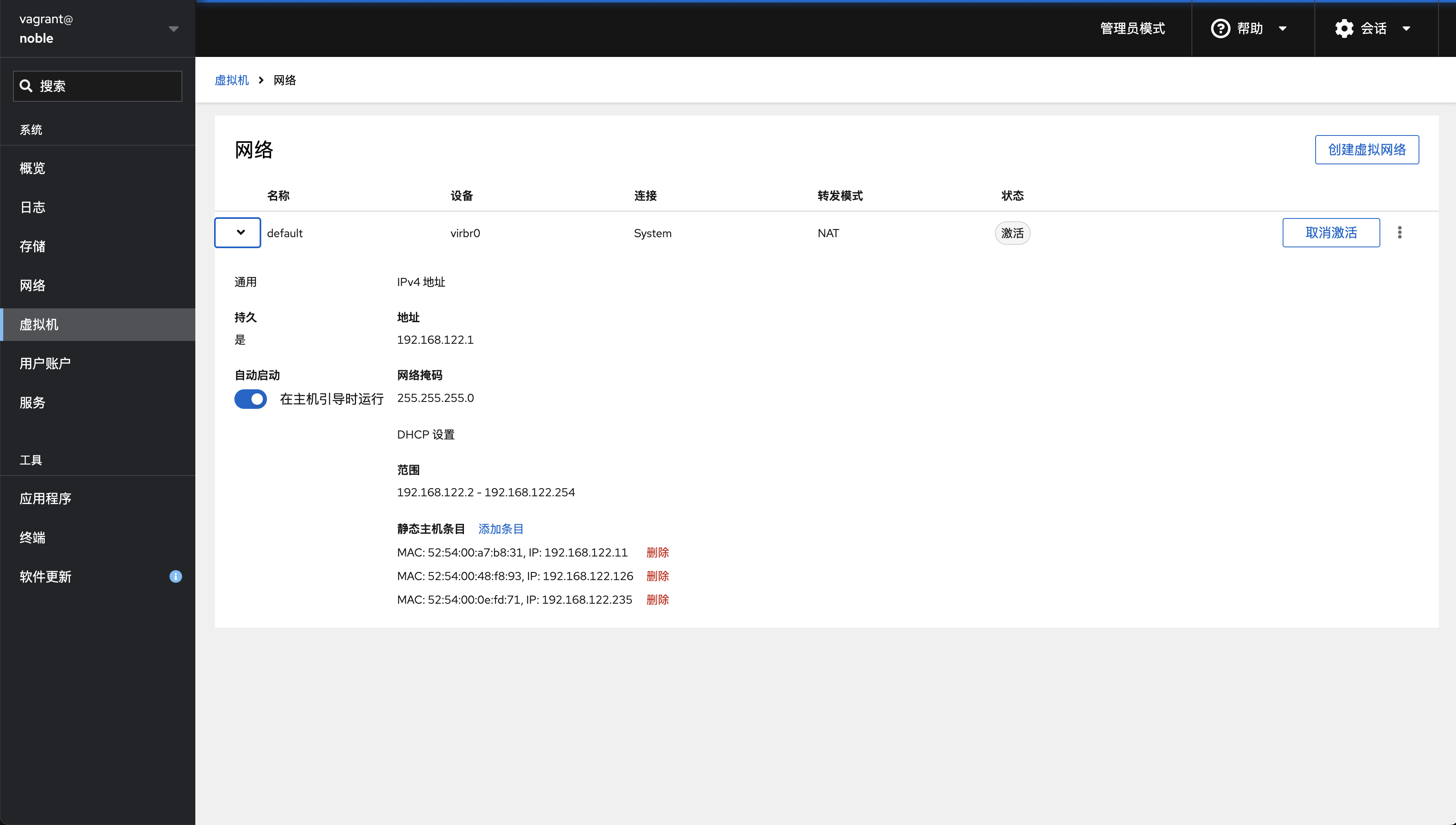
cockpit绑定MAC以及IP 点击添加【静态主机条目】,绑定mac地址与ip地址,避免重启一次机器就变一次IP
hosts修改 往hosts添加三台vm的host映射,移除127.0.0.1 vm1字样的的记录
1 2 3 4 5 192.168.0.105 registry.noname.io 192.168.122.11 vm1 192.168.122.126 vm2 192.168.122.235 vm3
部署k8s 好了,到这里就可以开始使用kubeadm初始化部署k8s集群了
执行kubeadm init 方法一,直接运行下面命令,比较适合简单的集群配置,不涉及太多配置修改
1 sudo kubeadm init --skip-phases addon/kube-proxy --apiserver-advertise-address 192.168.122.11 --node-name vm1 --image-repository registry.noname.io:5000
方法二,通过命令导出默认配置内容,修改相关配置,最后指定config文件运行
1 2 kubeadm config print init-defaults > kubeadm_config.yaml
把advertiseAddress、name、skipPhases、imageRepository等需要修改的地方全改了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 apiVersion: kubeadm.k8s.io/v1beta3 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 192.168 .122 .11 bindPort: 6443 nodeRegistration: criSocket: unix:///var/run/containerd/containerd.sock imagePullPolicy: IfNotPresent name: vm1 taints: null skipPhases: - addon/kube-proxy --- apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {}dns: {}etcd: local: dataDir: /var/lib/etcd imageRepository: registry.noname.io:5000 kind: ClusterConfiguration kubernetesVersion: 1.31 .0 networking: dnsDomain: cluster.local serviceSubnet: 10.96 .0 .0 /12 scheduler: {}
dry-run验证kubeadm_config.yaml文件
1 sudo kubeadm init --config kubeadm_config.yaml --dry-run
执行初始化
1 sudo kubeadm init --config kubeadm_config.yaml
正常情况下,只要没有中途退出报错,走到这里就是安装成功的第一步了。如果出现异常可以在初始化命令后面加-v 5打印更具体的报错信息,我也把遇到过的报错情况放到了最后的bug处理,接下来就是验证集群是否在正常工作了
PS:kubeadm提示可以在执行init命令前可以先拉取image,我试了一下kubeadm config images pull,发现init还是会去拉取image,上面就不在记录这个步骤
集群状态验证 配置bash
1 2 3 mkdir -p $HOME /.kubesudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/configsudo chown $(id -u):$(id -g) $HOME /.kube/config
执行命令,验证集群的工作状态。注意 :安装过程中如果有使用proxy会导致kubectl连接不上api server,导致超时,需要删除环境变量unset http_proxy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 sudo netstat -tnlp | grep 6443kubectl cluster-info kubectl get nodes -o wide kubectl describe nodes kubectl get pods -A -o wide kubectl logs <pod名称> -n <namespace> -p kubectl describe <pod名称> -n <namespace> -p sudo crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock ps -a
安装cilium 下载cilium,安装到/usr/local/bin/
1 2 3 4 5 6 curl -L --fail --remote-name-all https://github.com/cilium/cilium-cli/releases/download/v0.16.15/cilium-linux-amd64.tar.gz{,.sha256sum } sha256sum --check cilium-linux-amd64.tar.gz.sha256sumsudo mv cilium /usr/local/bin/
cilium查看组件安装情况以及报错信息,这里可以根据输出拉取相关image推送到私有registry,cni目录需要保证所有者是root
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 cilium status cilium install kubectl get pods -A -o wide kubectl get nodes
到这里集群的初始化就完成了,congratulations
其他 单节点k8s 如果你不想要组集群了,想使用单个节点,那么移除taint即可
1 2 3 kubectl taint nodes --all node-role.kubernetes.io/control-plane- kubectl taint nodes --all node-role.kubernetes.io/master-
配置proxy拉取镜像 如果你不想使用私有的registry,那么可以使用proxy,containerd的配置如下
1 2 3 4 sudo systemctl set-environment HTTP_PROXY=192.168.0.105:8118sudo systemctl set-environment HTTPS_PROXY=192.168.0.105:8118sudo systemctl restart containerd
然后,不论是直接执行kubeadm init还是kubeadm config images pull,拉取镜像都会通过proxy拉取
Dashboard UI 安装 方法一:使用helm安装(官方推荐)
1 2 3 4 helm repo add kubernetes-dashboard https://kubernetes.github.io/dashboard/ helm upgrade --install kubernetes-dashboard kubernetes-dashboard/kubernetes-dashboard --create-namespace --namespace kubernetes-dashboard
方法二:下载配置文件导入
1 2 kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
执行kubectl get pods -A,你会在kubernetes-dashboard命名空间下看到两个pod
1 2 3 NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kubernetes-dashboard dashboard-metrics-scraper-6b96ff7878-ct999 1/1 Running 0 6m57s 10.0.1.215 vm2 <none> <none> kubernetes-dashboard kubernetes-dashboard-8696f5f494-8cx4d 1/1 Running 0 6m57s 10.0.1.62 vm2 <none> <none>
如果无法拉取image,可以在物理机下载后推送到私有registry
1 2 docker pull kubernetesui/dashboard:v2.7.0 docker pull kubernetesui/metrics-scraper:v1.0.8
创建用户 新建文件dashboard-user.yaml,创建用户、绑定角色,如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 apiVersion: v1 kind: ServiceAccount metadata: name: dashboard-user namespace: kubernetes-dashboard --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: dashboard-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: dashboard-user namespace: kubernetes-dashboard
执行命令
1 kubectl apply -f dashboard-user.yaml
访问dashboard 1 2 3 4 5 6 7 8 9 kubectl proxy kubectl -n kubernetes-dashboard create token dashboard-user ssh -L 8001:127.0.0.1:8001 noname@192.168.122.11
在物理机浏览器打开dashboard页面:http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/ ,输入token即可进入dashboard界面
部署vm2/vm3 打印vm1的k8s token信息
1 kubeadm token create --print-join-command
在vm2/vm3执行命令,加入集群
1 2 sudo kubeadm join 192.168.122.11:6443 --token 1kf3mx.6omg1ycbi6xul19q \ --discovery-token-ca-cert-hash sha256:9a412686425ed09f8156ec63cb52e798a61cf8de85069be0e36ec023f806ea4f
在vm1验证集群状态
1 2 kubectl get nodes kubectl get pods -n kube-system
练习 以下列出几个简单的app部署教程,从简单到复杂
nginx-deployment
该教程是最简单的deployment使用教程,提供的功能是一个简单的http服务器,对外输出静态html页面,pod只有一个nginx的container,不涉及多container交互、存储等,该教程是一个很好的入门切入点
guestbook
该教程会教你如何部署一个redis主从服务、php服务,最后创建一个可对外的service,简单的说,是教你多个container如何交互并提供对外访问能力(集群内),这里不涉及存储、ingress等。应用提供的功能可以理解为动态http服务器,php从redis读取数据输出html页面、写入数据到redis
wordpress
该教程会教你如何创建持久卷保存数据,涉及mysql部署、wordpress部署、创建secret,到这里基本涵盖到平时大多数的使用场景了
注意 :由于该教程是基于minikube的,直接部署到自建的k8s集群会有很多问题,比如
不支持LoadBalancer,我们需要删除掉wordpress-deployment.yaml文件service声明配置里的type: LoadBalancer
缺少默认的storageclass,不支持动态制备,只能手动建立pv,然后在pvc关联pv,具体如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 apiVersion: v1 kind: PersistentVolume metadata: name: mysql-pv spec: capacity: storage: 20Gi accessModes: - ReadWriteOnce hostPath: path: /data/k8s/pv/mysql-pv --- apiVersion: v1 kind: PersistentVolume metadata: name: wp-pv spec: capacity: storage: 20Gi accessModes: - ReadWriteOnce hostPath: path: /data/k8s/pv/wp-pv
最后,在vm1节点执行命令创建端口转发
1 2 3 4 kubectl port-forward svc/wordpress 8888:80 ssh -L 8888:127.0.0.1:8888 noname@192.168.122.11
done!
后记 注意,按照以上教程安装的集群属于裸集群(bare-metal),默认不支持以下几个功能
Load Balancer Service
Persistent Volume
Ingress/Gateway
如果你的角色是开发者,还是老老实实使用Minikube,避免耗费太多时间精力在集群运维上
另外,一个完整的运维系统不仅仅只是k8s,应当包含以下组件
k8s,负责管理pod资源(cpu/内存)、node资源
分布式文件系统,负责持久存储
gateway,负责控制外部流量对集群内服务的访问
elk,负责日志收集、分析、告警
jaeger/prometheus,负责收集指标、链路分析、告警
ci/cd系统,如gitlab,负责开发-发布系统流程
管理后台,负责应用管理、发布审核、记录审计信息等
bug处理
kubeadm init执行后集群组件反复崩溃重启CrashLoopBackOff或者是卡在kubelet-check检查步骤
该问题原因与下面的cilium报错原因一致,软件权限导致的。在最开始时我使用的是手动安装方式,软件都是解压缩复制到bin目录,没有注意到所有组件的owner不是root,这才导致了上面这个问题。虽然是一个很容易忽视的问题,但却让我花了很长时间去debug,太亏了
cilium安装报错cp: cannot create regular file '/hostbin/cilium-mount': Permission denied
这是因为这个目录是我手动创建的,在执行apt安装前就存在,目录的owner不是root,需要确保虚拟机/opt/cni目录的所有者是root,执行sudo chown -R root:root /opt/cni解决,详细看:https://github.com/cilium/cilium/issues/23838
kubeadm join报错'/run/systemd/resolve/resolv.conf': No such file or directory
从服务器我换了一个debian,毕竟线上服务器通常都不是同一类系统,而这次报错的服务器bookworm就没有安装systemd-resolved,下载安装即可
1 sudo apt install systemd-resolved
上面debian的修改会引入另一个问题,就是vm无法连通外网了,发现是dhcp有异常,进而导致ImagePullBackOff,也不知道为什么不能直接读取本地的image,需要使用systemd-networkd才行,详细看问题描述Configuring systemd-networkd on Debian
1 2 3 4 5 mv /etc/network/interfaces /etc/network/interfaces.baksudo vi /etc/systemd/network/dhcp.network
dhcp.network文件内容如下
1 2 3 4 5 6 [Match] Name=en* [Network] DHCP=yes
设置开机启动并重启服务
1 2 sudo systemctl enable systemd-networkdsudo systemctl restart systemd-networkd
nginx-deployment报错ImagePullBackOff
这个问题很奇怪,除了前面提到的网络问题,还可能是hash值不匹配
当时我改了nginx-deployment.yaml 里的镜像,而且确认本地已经拉取过来了,但部署时就一直报错,最后我在物理机重新拉取镜像时发现hash值居然对不上,最后重新打tag推送才解决
参考文档 安装 kubeadm Simple Single-node Kubernetes Cluster via kubeadm on Ubuntu 22.04 How to Install Kubernetes Cluster on Debian 12 | 11 cilium在kubernetes中的生产实践二(cilium部署) The differences between Docker, containerd, CRI-O and runc Kubernetes Dashboard: Tutorial, Best Practices & Alternatives Creating sample user Is it OK to change /etc/machine-id? Kubernetes The Hard Way